
I am a senior undergraduate student with a strong interest in Multimodal LLMs, Tool-Using Agents and Spatial Intelligence. My research vision is to develop super-intelligent yet lightweight Multimodal LLMs, enabling machines to perceive, plan, reason, and act through the autonomous integration of multi-sensory signals, external tools, and knowledge, giving rise to superhuman yet controllable intelligence in downstream tasks such as Video Understanding, Embodied Robotics, Autonomous Driving, and Medical Diagnosis.
Research Interests and Highlights
-
Multimodal Intelligence: How can machines extract learnable neural-symbolic concepts from the complex physical world to enable grounded understanding, integration, interaction, and decision-making across multi-sensory signals, ultimately leading to superhuman yet interpretable intelligence?
-
Generative World Modeling and Spatial Intelligence: Toward multimodal superintelligence, guiding foundation models to deeply understand the underlying mechanisms of the complex physical world, internalize world dynamics within their parameter space, and reason about complex object properties and interactions in dynamic 3D environments.
-
In-the-wild Agents: How can we teach foundation models to see, plan, and act in open-world settings, while autonomously interacting with external environments such as tools, knowledge bases, and simulators, thereby continuously extending their capability boundaries in real-world applications?
🔥 News
- 2026.02: 🎉🎉 Our work fMRI-LM on Medical Foundation Models has been accepted by CVPR 2026!
- 2026.01: 🎉🎉 Three first/co-first author papers have been accepted by ICLR 2026!
- DecAlign: Aligning Cross-Modal Semantics for Multimodal Foundation Models
- AutoDrive-R²: Towards Physical-Grounded Multimodal Reasoning for Autonomous Driving
- Video-STAR: Tool-Augmented Agentic RL for Thinking with Videos
- 2026.01: 🎉🎉 We propose ProgressLM, which further investigates whether VLMs can acquire human-like, generalizable mental understanding and simulation in embodied scenarios from a single example, and serves as an early step toward building general-purpose reward models. See More: [Website] [Paper] [Code] [Model] [Dataset]
- 2025.11: 🎉🎉 Our work LiMT, an unified multi-task liver image benchmark work, has been accepted by Journal of Biomedical and Health Informatics (JBHI)!
- 2025.10: 🎉🎉 Our work DVP-MVS++, a multi-view stereo method that integrates depth-normal-edge priors and visibility guidance for robust 3D Reconstruction, has been accepted by IEEE Transactions on Circuits and Systems for Video Technology!
- 2025.10: 🎉🎉 My first-author work on Medical Segmentation under sparse and noisy labeled annotations has been accepted by BIBM AIBH 2025!
- 2025.10: 🎉🎉 We propose Video-STAR, a powerful Tool-Augmented Agentic RL approach for Thinking with Videos. On open-vocabulary action recognition benchmarks like K-400 and HMDB-51, our 3B VLM achieves nearly 40% accuracy improvement over base models!🔥
- 2025.09: 🎉🎉 Our work HALF-GS, an efficient dynamic 3D reconstruction framework combining sparse anchors, self-supervised guidance, and hierarchical propagation to improve reconstruction quality and temporal consistency, has been accepted by NeurIPS 2025!
- 2025.09: 🎉🎉 We propose AutoDrive-R², Incentivizing Reasoning and Self-Reflection Capacity for VLA Model in Autonomous Driving. We’re also honored that our work was featured by AutoDrive Heart (自动驾驶之心)!
- 2025.08: 🎉🎉 Our work Re-Align has been accepted by EMNLP 2025 Main Conference!
- 2025.07: 🎉🎉 Our work on Generalizable Medical Vision has been Accepted by IEEE Transactions on Medical Imaging.
- 2025.05: 🎉🎉 Our work CLIMD has been Early Accepted by MICCAI 2025 (Top 9%).
- 2025.03: 🎉🎉 Excited to propose my first-author work DecAlign, a novel cross-modal decoupling and alignment framwork for multimodal representation learning.
- 2024.11: 🎉🎉 Excited to propose my first-author work DynCIM, a novel dynamic multimodal curriculum learning framework in addressing cross-modal competition and imbalances, which is now available on ArXiv!
- 2024.10: 🎉🎉 We propose FASS, a novel frequency domain-enhanced approach for Medical Image Segmentation under Low-Contrast environment.
📝 Selected Publications
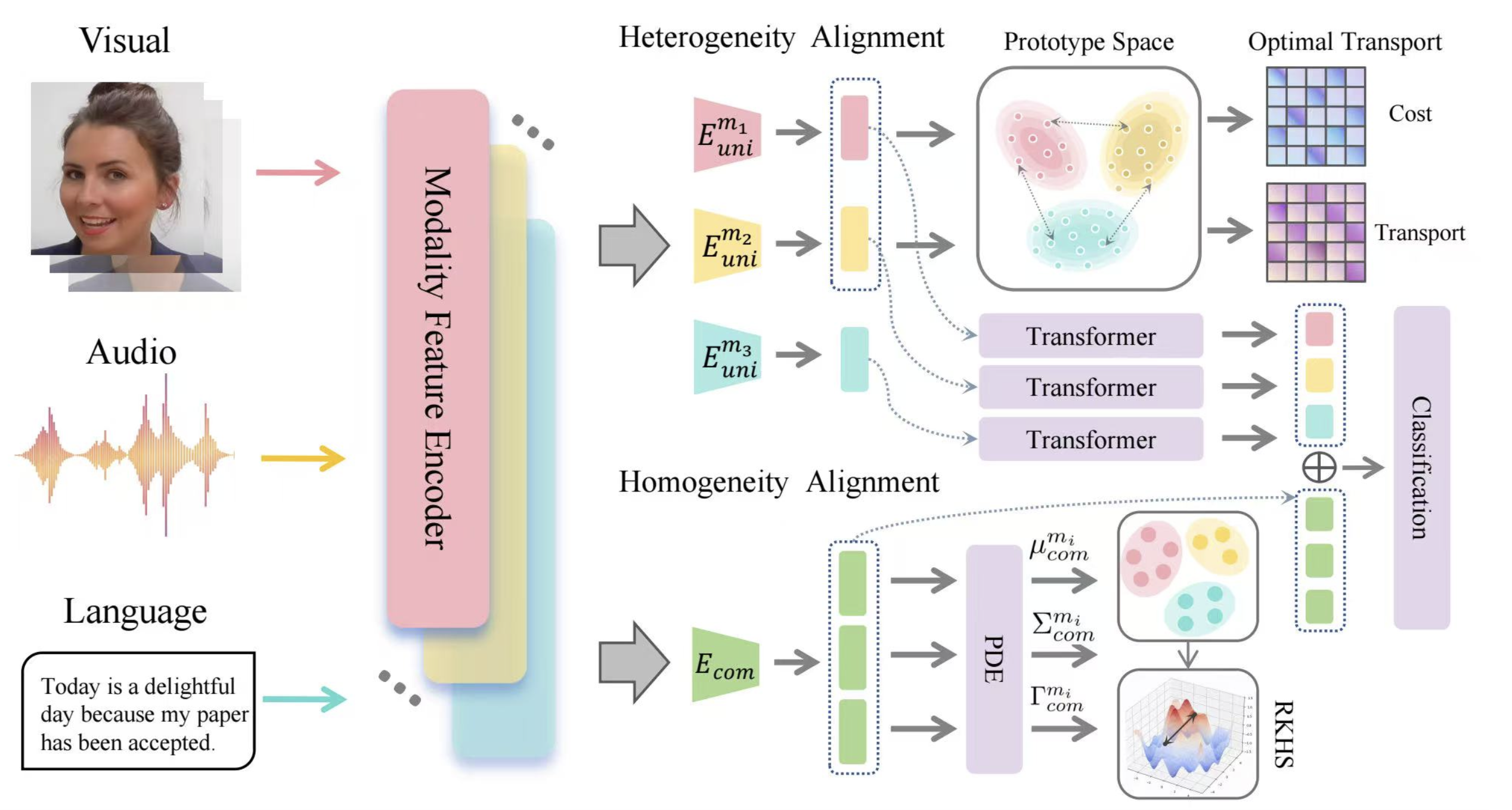
DecAlign: Hierarchical Cross-Modal Alignment for Decoupled Multimodal Representation Learning
Multimodal Alignment Foundation Model Interpretability
ICLR 2026
Chengxuan Qian, Shuo Xing, Shawn Li, Yue Zhao, Zhengzhong Tu†.


Multimodal Reasoning Autonomous Driving Open-World Applications
Featured by AutoDrive Heart (自动驾驶之心)
ICLR 2026
Zhenlong Yuan*, Chengxuan Qian*, Jing Tang, Jinguo Luo, Rui Chen, Lei Sun, Xiangxiang Chu, Yujun Cai, Dapeng Zhang, Shuo Li.
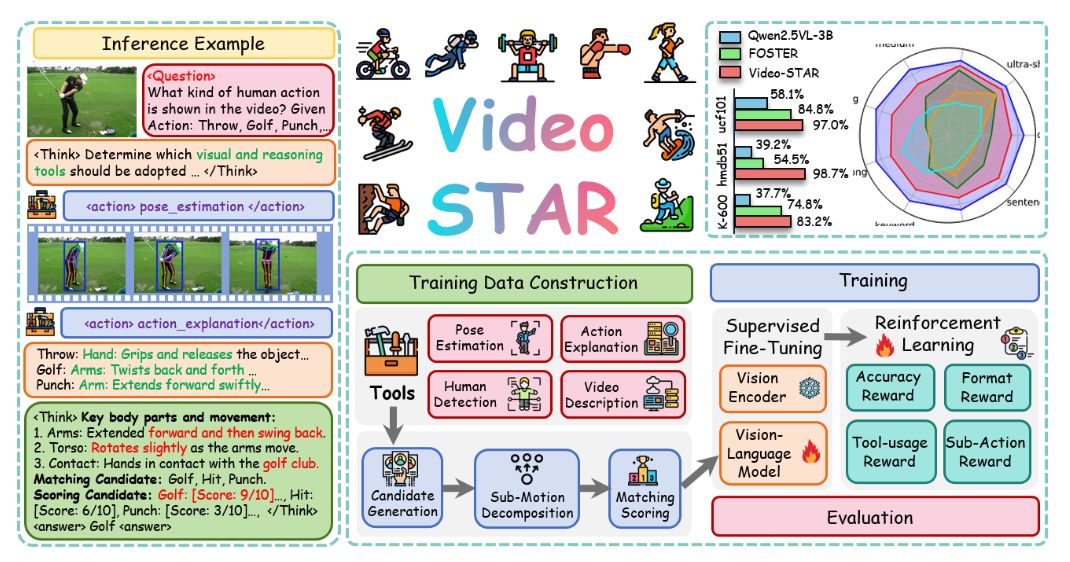
Video-STAR: Reinforcing Open-Vocabulary Action Recognition with Tools
Think with Videos Tool-Using Agent Multi-turn Agentic RL
ICLR 2026
Zhenlong Yuan, Xiangyan Qu, Chengxuan Qian†, Rui Chen, Jing Tang, Lei Sun, Xiangxiang Chu, Dapeng Zhang, Yiwei Wang, Yujun Cai, Shuo Li.
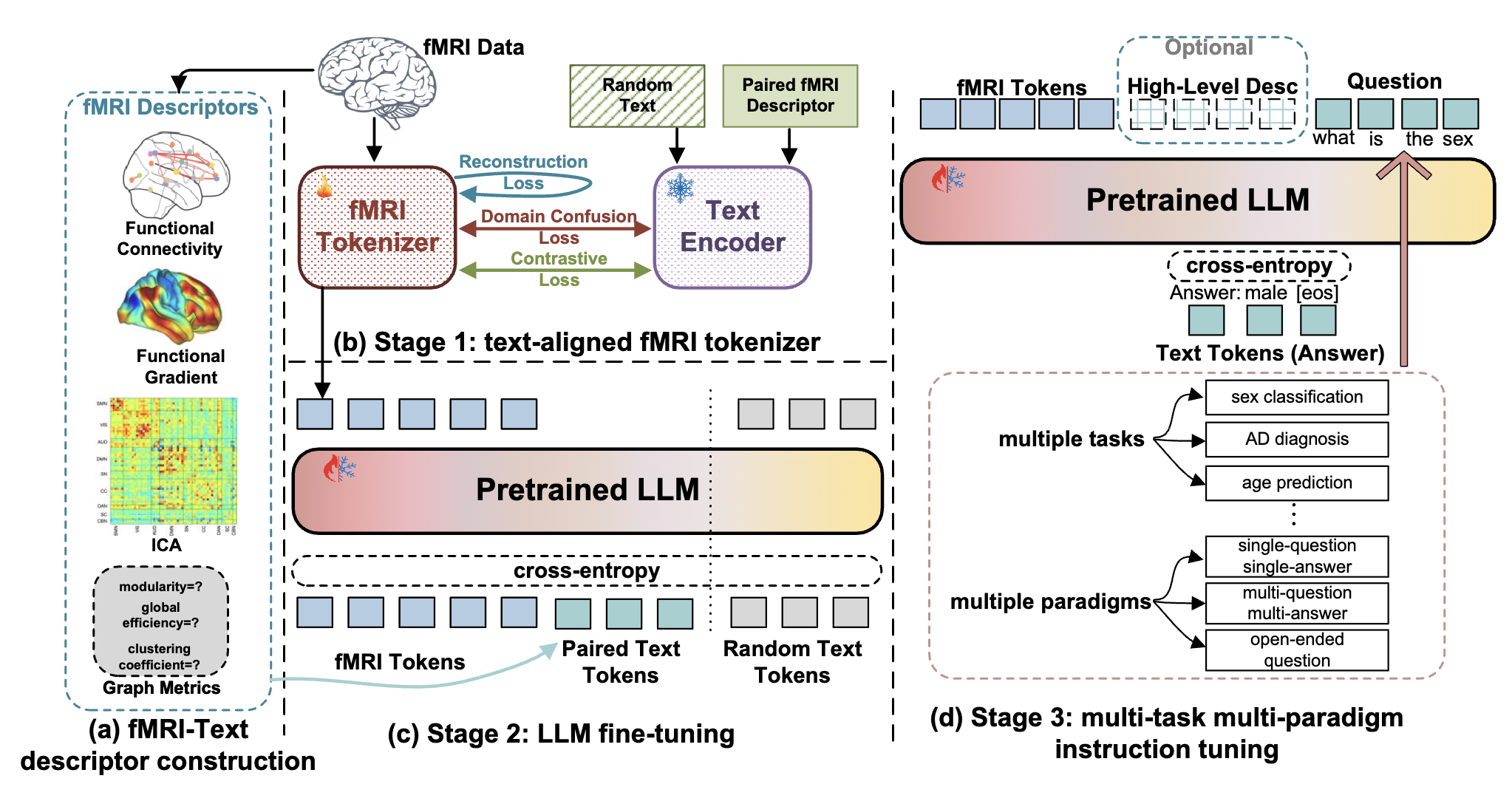
fMRI-LM: Towards a Universal Foundation Model for Language-Aligned fMRI Understanding
Medical LLMs Data-Centric Foundation Model
CVPR 2026
Yuxiang Wei, Yanteng Zhang, Xi Xiao, Chengxuan Qian, Tianyang Wang, Vince D. Calhoun †.
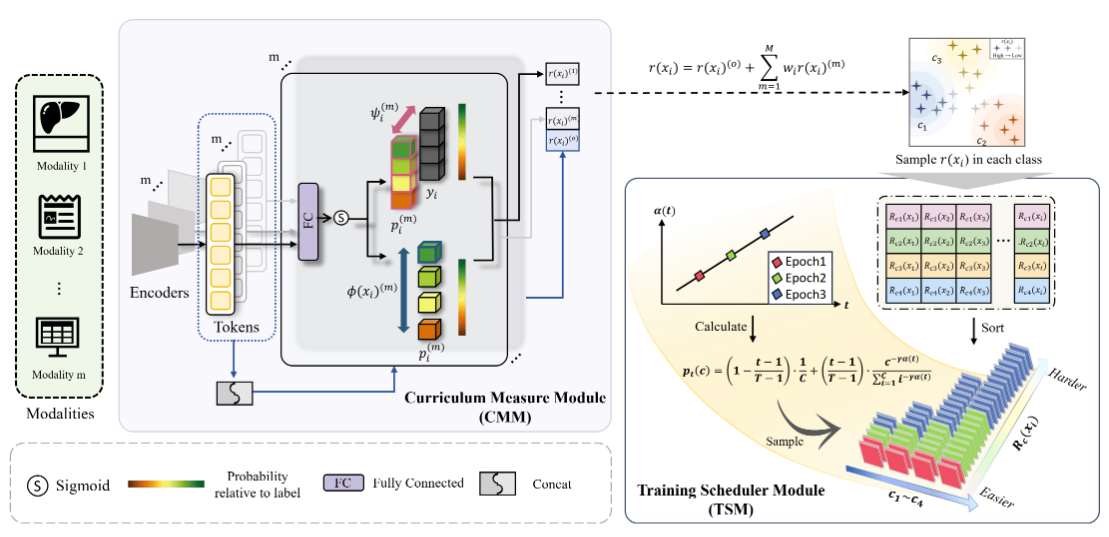
CLIMD: A Curriculum Learning Framework for Imbalanced Multimodal Diagnosis
Modality Imbalances Medical AI Curriculum Learning
MICCAI 2025 Early Accept (Top 9% Paper)
Kai Han, Chongwen Lyu, Chengxuan Qian, Siqi Ma, Jun Chen†, Zhe Liu†,
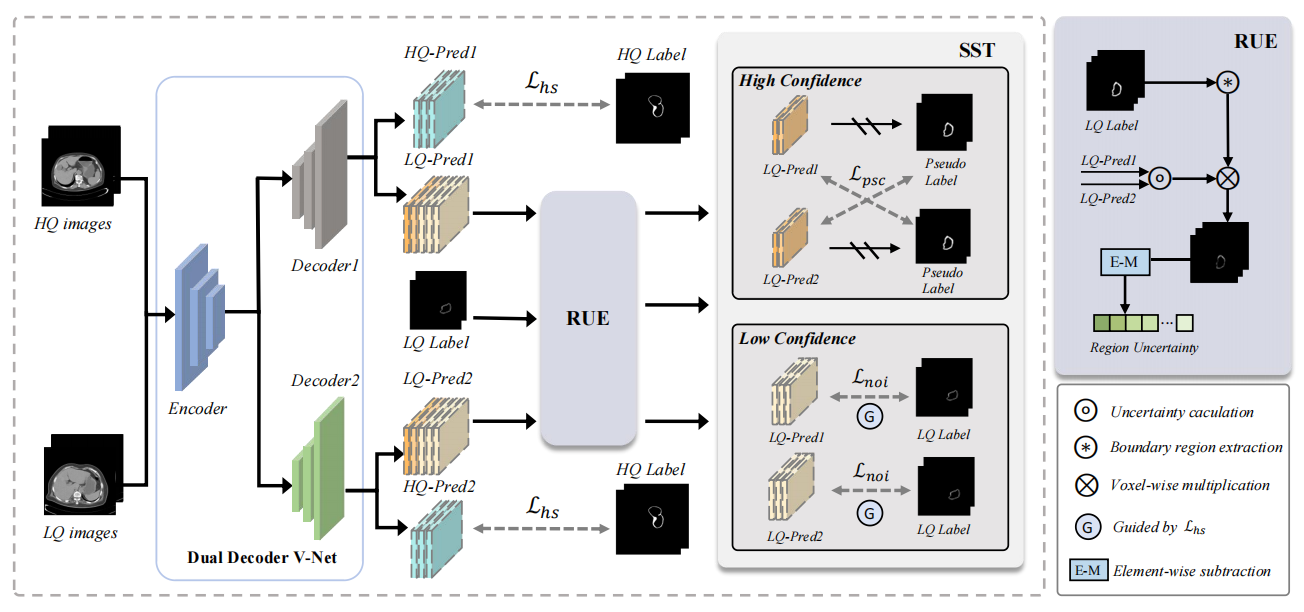
Region Uncertainty Estimation for Medical Image Segmentation with Noisy Labels
Medical Segmentation Noisy Labels Sparse Annotation Uncertainty Estimation
IEEE Transaction on Medical Imaging, 2025
Kai Han, Shuhui Wang, Jun Chen†, Chengxuan Qian, Chongwen Lyu, Siqi Ma, Victor S. Sheng†, Qingming Huang†, Zhe Liu†.
🌟 Misc
I’m grateful for the mentorship of Prof. Zhengzhong Tu (TAMU), Prof. Yue Zhao (USC), Prof. Han Liu & Manling Li (Northwestern University). Outside of research, I enjoy Photography📹, swimming🏊, biking🚴, billiards🎱, table tennis🏓. I strive to stay energetic every day and maintain a strong sense of passion for both academic research and life.
🎖 Academical Services
- Journal Reviewer: IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), IEEE Transactions on Multimedia (TMM).
- Conference Reviewer: ICME 2025-2026, AAAI 2026, ICASSP 2026, CVPR 2026
- Workshop Reviewer: ACL 2025 SRW, NeurIPS 2025 Imageomics, NeurIPS 2025 Efficient Reasoning